C++学习 关联容器
关联容器
容器分为顺序容器和关联容器,他们之间存在根本的区别,联容器中的元素是按关键字来保存和访问的。与之相对,顺序容器中的元素是按它们在容器中的位置来顺序保存和访问的。,主要顺序容器有vector、list、string、deque。主要的的关联容器有set、map。
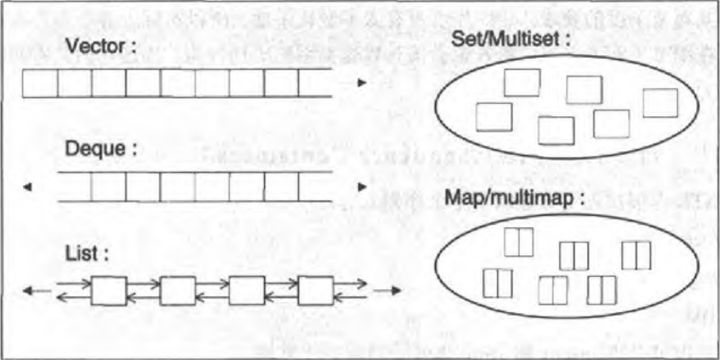

关联容器之map
map 由红黑树实现,其元素都是 “键值/实值” 所形成的一个对组(key/value pairs), 插入和搜索的平均复杂度均为O(log(size))。每个元素有一个键,是排序准则的基础。每一个键只能出现一次,不允许重复。字典则是一个很好的使用map的例子:可以将单词作为关键字,将单词释义作为值。
map类型通常被称为关联数组。
对于迭代器来说,可以修改实值,而不能修改 key。
map引申类型
1 | map :关联数组;保存关键字-值对;数据的存放是有序的 |
需要注意的是:类型map和multimap定义在头文件map中,unordered_map定义在头文件unordered_map中。
map的相关定义
类似顺序容器,关联容器也是模板。当定义一个map时,必须指明关键字类型又指明值类型。每个关联容器都定义了一个默认构造函数,它创建一个指定类型的空容器。我们也可以将关联容器初始化为另一个同类型容器的拷贝,或是从一个值范围来初始化关联容器,只要这些值可以转化为容器所需类型就可以。
1 | map<string,size_t> word_count; //string到size_t的空map |
map容器定义了如下列出的类型,这些类型表示容器关键字和值的类型。
1 | key_type map容器的关键字的类型 |
容器关键词的定义与使用
1 | map<string,int>::value_type v1; //v1是一个pair<const string,int> |
map的使用
当我们向顺序容器比如vector中插入元素时,我们可以使用push_back()函数将数据插入到容器尾部。但是关联容器不支持push_back()和push_front()的操作,所以我们想要往map中插入数据时,只能使用insert和emplace函数。
1 | c.insert(v) v是value_type类型的对象 |
遍历
当解引用一个关联容器迭代器时,我们会得到一个类型为容器的value_type的值的引用。对map容器而言,它的迭代器其实指向的是一个pair类型的对象。我们可以使用迭代器遍历map容器。
1 | auto map_it=word_count.cbegin(); |
访问元素
1 | auto it = word_count.find("foobar"); |
删除元素
1 | c.erase(key) //从c中删除关键字为key的元素。返回一个size_type的值,指出删除元素数量 |
优缺点和适用场景
优点:使用平衡二叉树实现,便于元素查找,且能把一个值映射成另一个值,可以创建字典。
缺点:每次插入值的时候,都需要调整红黑树,效率有一定影响。
适用场景:适用于需要存储一个数据字典,并要求方便地根据key找value的场景。
关联容器之multimap
不同点
添加元素
由于multimap中容器的关键字不必唯一,所以我们可以向multimap中插入多个关键字相同的元素。
1 | multimap<string,string> authors; |
下标访问
map支持下标访问。multimap中的一个关键字可能对应多个值,所以multimap并不支持下标操作。
查找元素
multimap一个关键字可能对应多个值,我们需要把这么对应的值都找出来。
如果multimap中有多个元素具有相同的关键字,则这些关键字在容器中会相邻存储。我们可以通过这一特性,将一个关键字对应的多个值全部找出来。
1 | string search_item("Alain"); |
关联容器之set
set:由红黑树实现,其内部元素依据其值自动排序,每个元素值只能出现一次,不允许重复,插入和搜索的平均复杂度均为O(log(size))。set 中的元素都是排好序的,集合中没有重复的元素。
定义与初始化
1 | set<string> a1={"fengxin","666"}; |
添加与删除
1 | set<string> a; //empty set |
遍历元素
同map容器类似。我们使用迭代器进行遍历set容器。需要注意的是,同不能改变一个map的关键字一样,一个set中的关键字也是const的。
1 | set<int> iset={0,1,2,3,4,5,6,7,8,9}; |
查找
由于set中存储的只有关键字,所以set容器并不支持下标操作。
set同样可以使用find函数进行对关键字的查找,此时函数返回指向关键字的迭代器。
1 | set<int> iset={0,1,2,3,4,5,6,7,8,9}; |
优缺点和适用场景
优点:使用红黑树实现,便于元素查找,且保持了元素的唯一性,以及能自动排序。
缺点:每次插入值的时候,都需要调整红黑树,效率有一定影响。
适用场景:适用于经常查找一个元素是否在某群集中且需要排序的场景。
严格弱序
关联容器之pair
pair定义
1 | pair<T1, T2> p1; //创建一个空的pair对象(使用默认构造),它的两个元素分别是T1和T2类型,采用值初始化。 |
关联容器操作

无序关联容器
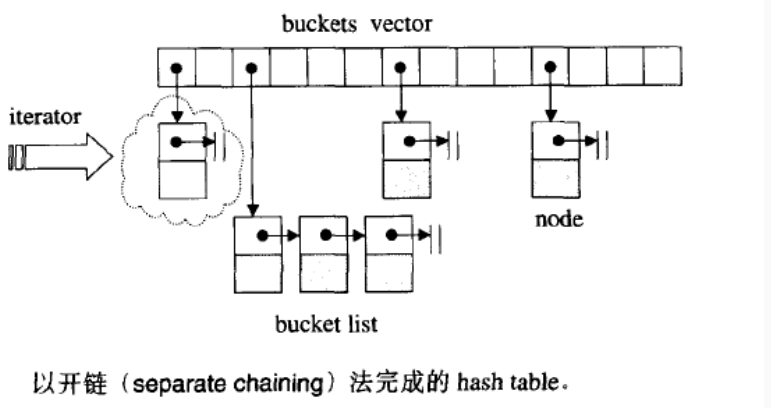
有序关联容器中的关键字是有序排列的,所以要求关键字可以进行<运算符比较或满足自定义的比较操作。无序关联容器不是使用比较运算符来组织元素,而是使用一个哈希函数和关键字类型的==运算符。
无序容器可以使用上述所有的与有序容器相同的操作,由于无序容器在存储上组织为桶,每个桶保存零个或多个元素,容器的性能依赖于哈希函数的质量和桶的数量和大小,因此无序容器多了一些哈希函数和桶相关的操作。
桶操作
1 | m.bucket_count() 正在使用的桶的数目 |
桶迭代
1 | local_iterator 可以用来访问桶中元素的迭代器类型 |
哈希策略
1 | //每个桶的平均元素数量,返回float值 |
自定义类型
内置类型包括指针可以直接定义hash,因此可以直接定义内置类型的无需容器,但是不能直接定义自定义类类型的无需容器,需要自定义hash模板。
1 | typedef unordered_map<string, double>::iterator MyIte; |
思考与总结
1、vector封装数组,list封装了链表,set, multiset, map, multimap内部采用的就是一种非常高效的平衡检索二叉树:红黑树。
2、std::map/std::set均为有序容器,这些元素内部通过红黑树进行实现, 插入和搜索的平均复杂度均为O(log(size))。在插入元素时候,会根据<操作符比较元素大小并判断元素是否相同, 并选择合适的位置插入到容器中。当对这个容器中的元素进行遍历时,输出结果会按照<操作符的顺序来逐个遍历。
空间占用率高,因为map内部实现了红黑树,虽然提高了运行效率,但是因为每一个节点都需要额外保存父节点,孩子节点以及红/黑性质,使得每一个节点都占用大量的空间,对于那些有顺序要求的问题,用map会更高效一些。
map、set中查找是使用二分查找,对速度影响分析
insert、erase之后,已保存的iterator失效问题。
3、unordered_map 因为内部实现了哈希表,因此其查找速度非常的快,但是哈希表的建立比较耗费时间对于查找问题,unordered_map会更加高效一些,因此遇到查找问题,常会考虑一下用unordered_map



